ANOVA View of Linear Models
David Gerard
2022-12-01
Learning Objectives
- ANOVA Perspective of hypothesis testing in the multiple linear regression model.
- Sections 6.5, 6.9, 7.1, 7.2, and 7.3 of KNNL
Sums of squares
Consider the multiple linear regression model \[ Y_i = \beta_0 + \beta_1 X_{i1} + \beta_2 X_{i2} + \cdots + \beta_{p-1}X_{i,p-1} + \epsilon_i \]
The error sum of squares associated with this model is the sum of squared residuals. \[ SSE(X_1,X_2,\ldots,X_{p-1}) = \sum_{i=1}^n\left[Y_i - (\hat{\beta}_0 + \hat{\beta}_1X_{i1} + \hat{\beta}_2X_{i2} + \cdots + \hat{\beta}_{p-1}X_{i,p-1})\right]^2 \]
For example, with one variable we have \[ SSE(X_1) = \sum_{i=1}^n\left[Y_i - (\hat{\beta}_0 + \hat{\beta}_1X_{i1})\right]^2 \] or \[ SSE(X_2) = \sum_{i=1}^n\left[Y_i - (\hat{\beta}_0 + \hat{\beta}_2X_{i2})\right]^2 \] etc.
With two variables we have \[ SSE(X_1,X_2) = \sum_{i=1}^n\left[Y_i - (\hat{\beta}_0 + \hat{\beta}_1X_{i1} + \hat{\beta}_2X_{i2} )\right]^2 \]
Note that the \(\hat{\beta}\)’s are generally different in the above SSE’s. That is, \(\hat{\beta}_1\) will be different if we fit the model \[ Y_i = \beta_0 + \beta_1 X_{i1} + \epsilon_i \] and obtain \(SSE(X_1)\), versus if we fit the model \[ Y_i = \beta_0 + \beta_1 X_{i1} + \beta_2 X_{i2} + \epsilon_i \] and obtain \(SSE(X_1,X_2)\), versus if we fit the model \[ Y_i = \beta_0 + \beta_1 X_{i1} + \beta_2 X_{i2} + \beta_3 X_{i3} + \epsilon_i \] and obtain \(SSE(X_1,X_2,X_3)\), etc…
That is, including new predictors affects the coefficient estimates of other predictors.
Each \(SSE\) measures how close the regression surface is to the data. Smaller means closer, larger means further away.
Let’s consider the Body Data example from Table 7.1 of KNNL. Variables include
triceps: Triceps skinfold thickness.thigh: Thigh circumference.midarm: Midarm circumferencefat: Body fat.
The goal is to predict body fat from the other variables. You can load these data into R using:
library(tidyverse) library(broom) body <- read_csv("https://dcgerard.github.io/stat_415_615/data/body.csv") glimpse(body)## Rows: 20 ## Columns: 4 ## $ triceps <dbl> 19.5, 24.7, 30.7, 29.8, 19.1, 25.6, 31.4, 27.9, 22.1, 25.5, 31… ## $ thigh <dbl> 43.1, 49.8, 51.9, 54.3, 42.2, 53.9, 58.5, 52.1, 49.9, 53.5, 56… ## $ midarm <dbl> 29.1, 28.2, 37.0, 31.1, 30.9, 23.7, 27.6, 30.6, 23.2, 24.8, 30… ## $ fat <dbl> 11.9, 22.8, 18.7, 20.1, 12.9, 21.7, 27.1, 25.4, 21.3, 19.3, 25…Then if we regress body fat on midarm, we obtain
lmmid <- lm(fat ~ midarm, data = body) lmmid## ## Call: ## lm(formula = fat ~ midarm, data = body) ## ## Coefficients: ## (Intercept) midarm ## 14.687 0.199The estimated regression function is \[ y = 14.7 + 0.2x \] and the error sum of squares is
amid <- augment(lmmid) sum(amid$.resid^2)## [1] 485.3\[ SSE(midarm) = 485.3 \] If we regress body fat on both midarm and thigh, then we obtain
lm_mid_thigh <- lm(fat ~ midarm + thigh, data = body) lm_mid_thigh## ## Call: ## lm(formula = fat ~ midarm + thigh, data = body) ## ## Coefficients: ## (Intercept) midarm thigh ## -25.997 0.096 0.851The estimated regression function is \[ y = -26.00 + 0.10x_1 + 0.85x_2 \] and the error sum of squares is
a_mt <- augment(lm_mid_thigh) sum(a_mt$.resid^2)## [1] 111.1- Notice that the coefficient estimate for
midarmchanged between these two fits. - Notice that the SSE decreased when we added thigh.
NOTE: The SSE will always decrease as you add more predictors (more accurately, it never increases). So, by itself, it is not a good indication of model quality, since it is not always better to add more predictors to a model.
\[ SSE(X_1) \geq SSE(X_1, X_2) \geq SSE(X_1, X_2, X_3) \text{ etc...} \]
But looking at SSE reductions can tell us how much more variability can be explained by adding predictors.
The extra sum of squares \[ SSR(X_1|X_2) = SSE(X_2) - SSE(X_1, X_2)\\ SSR(X_2|X_1) = SSE(X_1) - SSE(X_1, X_2)\\ SSR(X_1, X_2|X_3) = SSE(X_3) - SSE(X_1, X_2, X_3)\\ \text{ etc...} \]
Recall: The regression sum of squares is how much the total sum of squares is reduced by including a covariate in the model. \[ SSR(X_1) = SSTO - SSE(X_1)\\ SSR(X_2) = SSTO - SSE(X_2)\\ SSR(X_1, X_2) = SSTO - SSE(X_1, X_2)\\ etc... \] It is how much variability is accounted for by the regression model.
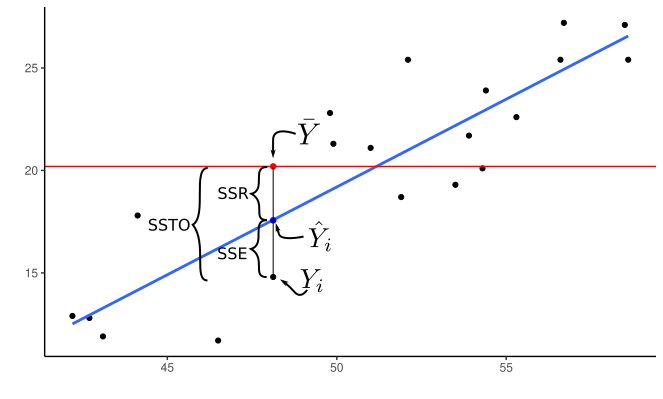
We can use this to show that the extra sum of squares is also how much the regression sum of squares improves
\[ SSR(X_1|X_2) = SSR(X_1, X_2) - SSR(X_2)\\ SSR(X_2|X_1) = SSR(X_1, X_2) - SSR(X_1)\\ SSR(X_1, X_2|X_3) = SSR(X_1, X_2, X_3) - SSR(X_3)\\ \text{ etc...} \]
Proof: \[\begin{align} SSR(X_1|X_2) &= SSE(X_2) - SSE(X_1, X_2)\\ &= [SSTO - SSR(X_2)] - [SSTO - SSR(X_1, X_2)]\\ &= SSR(X_1, X_2) - SSR(X_2). \end{align}\]
Exercise: True/False and explain: The regression sum of squares never decreases as you include more covariates in a model.
Exercise: Express \(SSR(X_1, X_3 | X_2, X_4)\) both in terms of error sums of squares and in terms of regression sums of squares.
The total sum of squares can be decomposed using regression sum of squares, extra sum of squares, and error sum of squares as follows:
\[ SSTO = SSR(X_1) + SSR(X_2|X_1) + SSR(X_3|X_1, X_2) + SSE(X_1, X_2, X_3) \] with the pattern continuing if more covariates are in the model.
The order of covariates does not matter
\[ SSTO = SSR(X_3) + SSR(X_2|X_3) + SSR(X_1|X_2, X_3) + SSE(X_1, X_2, X_3) \]
Many researchers will represent regression results in terms of this sum of squares decomposition.
E.g. in R if you use the
anova()function on thelmobject, you get the decompositionSS SSR(\(X_1\)) SSR(\(X_2\)|\(X_1\)) SSR(\(X_3\)|\(X_2\),\(X_1\)) SSE(\(X_1\), \(X_2\), \(X_3\)) lm_all <- lm(fat ~ triceps + thigh + midarm, data = body) anova(lm_all)## Analysis of Variance Table ## ## Response: fat ## Df Sum Sq Mean Sq F value Pr(>F) ## triceps 1 352 352 57.28 1.1e-06 ## thigh 1 33 33 5.39 0.034 ## midarm 1 12 12 1.88 0.190 ## Residuals 16 98 6In the above R output, if \(X_1\) = triceps, \(X_2\) = thigh, and \(X_3\) = midarm, then we have
- \(SSR(X_1) = 352\)
- \(SSR(X_2|X_1) = 33\)
- \(SSR(X_3|X_1, X_2) = 12\)
- \(SSE = 98\).
The SSTO is then the sum of these values: \(SSTO = 352 + 33 + 12 + 98 = 495\). We can verify this in R
## SSTO sum((body$fat - mean(body$fat))^2)## [1] 495.4Showing the sum of squares in this pattern is called “Type I Sum of Squares”.
Other researchers display the “Type II Sum of Squares”:
SS SSR(\(X_1\)|\(X_2\), \(X_3\)) SSR(\(X_2\)|\(X_1\), \(X_3\)) SSR(\(X_3\)|\(X_2\),\(X_1\)) SSE(\(X_1\), \(X_2\), \(X_3\)) The easiest way to get Type II Sum of Squares is through the
Anova()function in the{car}packagelibrary(car) Anova(lm_all)## Anova Table (Type II tests) ## ## Response: fat ## Sum Sq Df F value Pr(>F) ## triceps 12.7 1 2.07 0.17 ## thigh 7.5 1 1.22 0.28 ## midarm 11.5 1 1.88 0.19 ## Residuals 98.4 16Exercise: In the above output, using \(X_1\) = triceps, \(X_2\) = thigh, and \(X_3\) = midarm, what is \(SSR(X_1|X_2, X_3)\), \(SSR(X_2|X_1, X_3)\), \(SSR(X_3|X_1, X_2)\), and \(SSE(X_1, X_2, X_3)\)?
Exercise: Does the Type II sum of squares ANOVA table provide us with enough information to calculate SSTO?
Hypothesis Testing
Why am I torturing you with sums of squares?
Sums of squares have two uses
- Discussing proportionate decline in variability when you add a predictor.
- Hypothesis testing.
E.g. “Adding tricep skinfold thickness decreased the sum of squares by 352, but adding in thigh only decreased it by an additional 33.”
Whether this is a big or small reduction is completely context dependent.
For hypothesis testing, suppose we are considering two nested models (null model is a subset of the alternative model)
\(H_0: Y_i = \beta_0 + \beta_1 X_{i1} + \cdots + \beta_qX_{i,q-1} + \epsilon_i\)
\(H_A: Y_i = \beta_0 + \beta_1 X_{i1} + \cdots + \beta_qX_{i,q-1} + \beta_{q}X_{i,q} + \cdots + \beta_{p-1}X_{i,p-1} + \epsilon_i\)
That is, the null model does not include \(X_{q},\ldots,X_{p-1}\).
Exercise: What values of \(\beta_q, \beta_{q+1},\ldots,\beta_{p-1}\) would turn the model under the alternative into the model under the null?
Let \(SSE(R) = SSE(X_1,X_2,\ldots,X_{q-1})\) be the sum of squares under the reduced model.
Let \(df_r = n - q\) be the degrees of freedom of the reduced model (sample size minus number of parameters).
Let \(SSE(F) = SSE(X_1,X_2,\ldots,X_{p-1})\) be the sum of squares under the full model.
Let \(df_f = n - p\) be the degrees of freedom of the full model (sample size minus number of parameters).
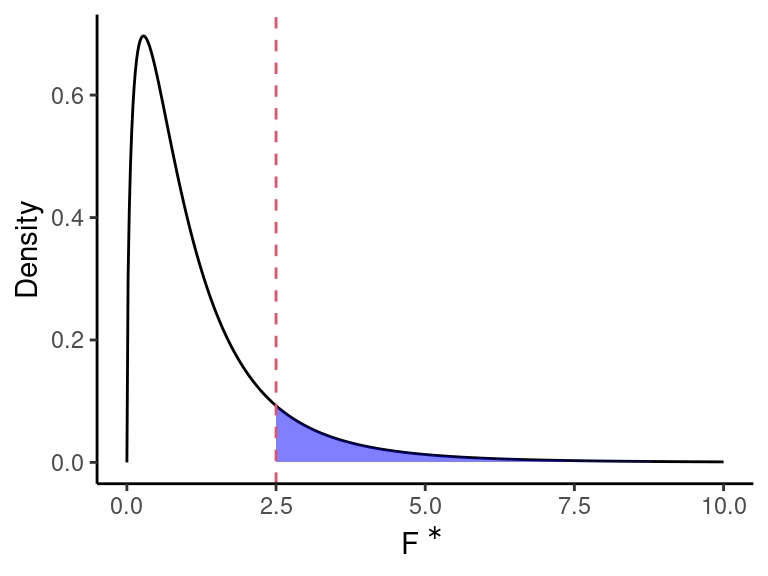
The test statistic is \[ F^* = \frac{[SSE(R) - SSE(F)] / (df_r - df_f)}{SSE(F) / df_f} \]
Under \(H_0\), we have \[ F^* \sim F(df_r - df_f, df_f) \]
Under \(H_A\), \(F^*\) would not follow this distribution, and would be larger than expected.
- This is because the reduction in the error sums of squares (\(SSE(R) - SSE(F)\)) would be larger than expected by chance alone.
So we can obtain a \(p\)-value via \(\text{qf}(F^*, df_r - df_f, df_f, \text{lower.tail = FALSE})\).
NOTE: The null will be rejected if at least one of the unincluded variables have non-zero coefficients. That is, it is not necessarily that case that all \(\beta_q,\beta_{q+1},\ldots,\beta_{p-1}\) are non-zero. So we can re-write the hypotheses as
- \(H_0: \beta_q = \beta_{q+1} = \cdots = \beta_{p-1} = 0\)
- \(H_A:\) At least one of \(\beta_q,\beta_{q+1},\ldots,\beta_{p-1}\) is non-zero.
NOTE: We can re-write the \(F\)-statistic in terms of extra sums of squares \[ F^* = \frac{[SSR(X_q,X_{q+1},\ldots,X_{p-1}|X_1,X_2,\ldots,X_{q-1})] / (df_r - df_f)}{SSE(F) / df_f} \]
In which case, the extra degrees of freedom is \(df_r - df_f\), which is the difference in the number of parameters in the full versus reduced model, \(p - q\).
Applications of \(F\)-test
Overall \(F\)-test
Consider the testing if at least one variable is associated with our response:
- \(H_0: \beta_1 = \beta_2 = \cdots = \beta_{p-1} = 0\)
- \(H_A:\) At least one \(\beta_1,\beta_{2},\ldots,\beta_{p-1}\)
Then under the null \[ F^* \sim F(p-1, n - p) \]
Exercise: What is the degrees of freedom of the reduced model?
Exercise: What is the degrees of freedom of the full model?
Exercise: What is the extra degrees of freedom?
In R, the overall \(F\) test is done automatically and is included in the output of
glance()from the{broom}package. It is thep.valueterm. Thestatisticterm is \(F^*\).lm_all <- lm(fat ~ triceps + thigh + midarm, data = body) glance(lm_all)## # A tibble: 1 × 12 ## r.squ…¹ adj.r…² sigma stati…³ p.value df logLik AIC BIC devia…⁴ df.re…⁵ ## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <int> ## 1 0.801 0.764 2.48 21.5 7.34e-6 3 -44.3 98.6 104. 98.4 16 ## # … with 1 more variable: nobs <int>, and abbreviated variable names ## # ¹r.squared, ²adj.r.squared, ³statistic, ⁴deviance, ⁵df.residualWe can verify this manually
a_all <- augment(lm_all) sse_f <- sum(a_all$.resid^2) df_f <- nrow(body) - 4 ## four parameters sse_r <- sum((body$fat - mean(body$fat))^2) df_r <- nrow(body) - 1 ## one parameter (beta_0) F_star <- ((sse_r - sse_f) / (df_r - df_f)) / (sse_f / df_f) F_star## [1] 21.52pf(q = F_star, df1 = df_r - df_f, df2 = df_f, lower.tail = FALSE)## [1] 7.343e-06
\(F\)-test for one variable
If we want to test whether we should include one more variable in the model, we would consider the hypotheses
- \(H_0: \beta_k = 0\)
- \(H_A: \beta_k \neq 0\).
If there are \(p-1\) variables in the full model, then the full degrees of freedom would be \(df_f = n - p\).
The degrees of freedom of the reduced model would be \(df_r = n - (p - 1) = n - p + 1\).
The extra degrees of freedom would be \((n - p + 1) - (n - p) = n - p + 1 - n + p = 1\). This is the number of parameters different between the two models.
Exercise: Suppose we have three variables and we are testing if \(\beta_2\) should be 0. Write out the full and reduced models.
Thus, the we have under the null that \[ F^* \sim F(1, n - p) \]
In R, you can obtain the result of all of these tests using
Anova()from the{car}package.lm_all <- lm(fat ~ triceps + thigh + midarm, data = body) Anova(lm_all)## Anova Table (Type II tests) ## ## Response: fat ## Sum Sq Df F value Pr(>F) ## triceps 12.7 1 2.07 0.17 ## thigh 7.5 1 1.22 0.28 ## midarm 11.5 1 1.88 0.19 ## Residuals 98.4 16The output above returns
Sum Sq Df F value Pr(>F) triceps SSR(\(X_1\)|\(X_2\), \(X_3\)) \(df_{extra} = 1\) for the test \(H_0:\beta_1 = 0\) \(F^*\) for the test \(H_0:\beta_1 = 0\) \(p\)-value for the test \(H_0:\beta_1 = 0\) thigh SSR(\(X_2\)|\(X_1\), \(X_3\)) \(df_{extra} = 1\) for the test \(H_0:\beta_2 = 0\) \(F^*\) for the test \(H_0:\beta_2 = 0\) \(p\)-value for the test \(H_0:\beta_2 = 0\) midarm SSR(\(X_3\)|\(X_1\),\(X_2\)) \(df_{extra} = 1\) for the test \(H_0:\beta_3 = 0\) \(F^*\) for the test \(H_0:\beta_3 = 0\) \(p\)-value for the test \(H_0:\beta_3 = 0\) Residuals SSE(\(X_1\), \(X_2\), \(X_3\)) n-p Let’s verify one of these manually.
First, we’ll fit a reduced model without
tricepslm_tm <- lm(fat ~ thigh + midarm, data = body)Now, let’s get the sums of squares and degrees of freedom.
a_full <- augment(lm_all) a_red <- augment(lm_tm) sse_full <- sum(a_full$.resid^2) sse_red <- sum(a_red$.resid^2) df_full <- nrow(body) - 4 df_red <- nrow(body) - 3 f_star <- ((sse_red - sse_full) / (df_red - df_full)) / (sse_full / df_full) f_star## [1] 2.066pf(q = f_star, df1 = df_red - df_full, df2 = df_full, lower.tail = FALSE)## [1] 0.1699
Recall, we already came up with a way to test against the null of \(H_0: \beta_k = 0\) using \(t\)-statistics.
tidy(lm_all)## # A tibble: 4 × 5 ## term estimate std.error statistic p.value ## <chr> <dbl> <dbl> <dbl> <dbl> ## 1 (Intercept) 117. 99.8 1.17 0.258 ## 2 triceps 4.33 3.02 1.44 0.170 ## 3 thigh -2.86 2.58 -1.11 0.285 ## 4 midarm -2.19 1.60 -1.37 0.190It turns out that using the \(F\)-test and the \(t\)-test are equivalent. So no need to worry about which one to use.
\(F\)-test for multiple variables.
Consider the Real Estate Sales data, which you can read about here and download from here.
Suppose we wanted to explore the relationship between log-price, log-area, log-lot size, and bed-number.
estate <- read_csv("https://dcgerard.github.io/stat_415_615/data/estate.csv") estate <- mutate(estate, log_price = log(price), log_area = log(area), log_lot = log(lot)) estate <- select(estate, log_price, log_area, log_lot, bed) glimpse(estate)## Rows: 522 ## Columns: 4 ## $ log_price <dbl> 12.79, 12.74, 12.43, 12.23, 12.53, 12.42, 12.35, 11.92, 12.1… ## $ log_area <dbl> 8.017, 7.629, 7.484, 7.401, 7.694, 7.584, 7.703, 7.376, 7.39… ## $ log_lot <dbl> 10.009, 10.039, 9.969, 9.761, 9.989, 9.847, 9.833, 10.004, 9… ## $ bed <dbl> 4, 4, 4, 4, 4, 4, 3, 2, 3, 3, 7, 3, 5, 5, 3, 5, 2, 3, 4, 3, …We want to regress log-price (\(Y\)) on log-area (\(X_1\)), log-lot (\(X_2\)), and bed number (\(X_3\)). Suppose we have already decided to include bed number, and we want to ask if we should include one of log-price and log-area. Then the two models that we care considering
- Reduced: \(Y_i = \beta_0 + \beta_3 X_{3i} + \epsilon_i\)
- Full: \(Y_i = \beta_0 + \beta_1 X_{i1} + \beta_2 X_{i2} + \beta_3 X_{i3} + \epsilon_i\)
In other words, we are testing
- \(H_0: \beta_1 = \beta_2 = 0\).
- \(H_A:\) At least one \(\beta_1\) or \(\beta_2\) is not zero.
The reduced model as \(df_r = n - 2\) degrees of freedom and the full model has \(df_f = n-4\) degrees of freedom. That means the extra degrees of freedom is \(df_{extra} = df_r - df_f = 2\).
So under the null \[ F^* \sim F(df_r - df_f, df_f) \]
To do this in R, we need to separately fit the full and reduced models.
lm_estate_reduced <- lm(log_price ~ bed, data = estate)
lm_estate_full <- lm(log_price ~ log_area + log_lot + bed, data = estate)We then insert both models into
anova()(notAnova()):anova(lm_estate_reduced, lm_estate_full)## Analysis of Variance Table ## ## Model 1: log_price ~ bed ## Model 2: log_price ~ log_area + log_lot + bed ## Res.Df RSS Df Sum of Sq F Pr(>F) ## 1 520 74.3 ## 2 518 25.5 2 48.8 496 <2e-16The output above returns:
Res.Df RSS Df Sum of Sq F Pr(>F) \(df_{r}\) SSE(\(X_3\)) \(df_f\) SSE(\(X_1, X_2, X_3\)) \(df_{extra}\) SSR(\(X_1, X_2|X_3\)) \(F^*\) for the test of \(H_0: \beta_1 = \beta_2 = 0\) \(p\)-value for the test of \(H_0: \beta_1 = \beta_2 = 0\) From the above output, we have
- \(df_r = 520\)
- \(df_f = 518\)
- \(SSE(X_3) = 74.3\)
- \(SSE(X_1, X_2, X_3) = 25.5\)
- \(df_{extra} = 2\)
- \(SSE(X_1, X_2|X_3) = 48.8\)
- \(F^* = 496\)
- \(p\)-value is the
<2e-16, indicating very strong evidence for including at least one of log-area and log-lot.
Exercise: Fill in the blanks of the following ANOVA table:
## Analysis of Variance Table ## ## Model 1: log_price ~ log_area ## Model 2: log_price ~ log_area + log_lot + bed ## Res.Df RSS Df Sum of Sq F Pr(>F) ## 1 20.4 ## 2 296 2 1.22 9.41 0.00011
\(F\)-test for including a categorical variable
We will use the earnings data for this example, which you can read about here and download from here
earnings <- read_csv("https://dcgerard.github.io/stat_415_615/data/earnings.csv")We will consider fitting a model of log-earnings on ethnicity and height.
earnings <- mutate(earnings, log_earn = log(earn)) earnings <- select(earnings, log_earn, ethnicity, height) earnings <- filter(earnings, is.finite(log_earn)) glimpse(earnings)## Rows: 1,629 ## Columns: 3 ## $ log_earn <dbl> 10.820, 11.002, 10.309, 10.127, 10.820, 11.035, 10.840, 9.10… ## $ ethnicity <chr> "White", "White", "White", "White", "Other", "Black", "White… ## $ height <dbl> 74, 66, 64, 65, 63, 68, 63, 64, 62, 73, 72, 72, 72, 70, 68, …Recall that we can encode a categorical variable with \(c\) classes in terms of \(c-1\) indicator variables.
For example, the variable
ethnicitywith \(c = 4\) values## [1] "White" "Other" "Black" "Hispanic"can be encoded with with variables
## # A tibble: 4 × 5 ## `(Intercept)` ethnicityHispanic ethnicityOther ethnicityWhite race ## <dbl> <dbl> <dbl> <dbl> <chr> ## 1 1 0 0 1 White ## 2 1 0 1 0 Other ## 3 1 0 0 0 Black ## 4 1 1 0 0 HispanicThat is,
- black individuals are coded \(X_1 = X_2 = X_3 = 0\),
- hispanic individuals are coded as \(X_1 = 1\) and \(X_2 = X_3 = 0\),
- white individuals are coded as \(X_3 = 1\) and \(X_1 = X_2 = 0\), and
- other individuals are coded as \(X_2 = 1\) and \(X_1 = X_3 = 0\).
If we also include \(X_4\) = height, then we can test for whether or not to include ethnicity in the model by comparing the two models
- \(H_0: Y_i = \beta_0 + \beta_4 X_{i4} + \epsilon_i\)
- \(H_A: Y_i = \beta_0 + \beta_1X_{i1} + \beta_2 X_{i2} + \beta_3 X_{i3} + \beta_4 X_{i4} + \epsilon_i\)
This is exactly what an \(F\)-test is useful for.
The \(df_f\) in this case is \(n-5\) while the \(df_r\) is \(n-2\), so the \(df_{extra}\) is \((n-2) - (n-5) = 3\).
We compare the resulting \(F^*\) to a \(F(3, n-5)\) distribution to obtain the \(p\)-value.
In R, when you use a categorical variable in
lm(), it will automatically convert the variable to indicators.lm_earn <- lm(log_earn ~ ethnicity + height, data = earnings) tidy(lm_earn)## # A tibble: 5 × 5 ## term estimate std.error statistic p.value ## <chr> <dbl> <dbl> <dbl> <dbl> ## 1 (Intercept) 5.82 0.380 15.3 1.52e-49 ## 2 ethnicityHispanic -0.0315 0.114 -0.277 7.82e- 1 ## 3 ethnicityOther 0.244 0.165 1.48 1.38e- 1 ## 4 ethnicityWhite 0.184 0.0719 2.56 1.05e- 2 ## 5 height 0.0561 0.00563 9.96 9.89e-23Notice that the output returns only the \(p\)-values for tests of whether to include each indicator variable. This is rarely helpful. Use
Anova()from the{car}package to obtain the \(p\)-value from the \(F\)-test of whether to include the ethnicity variable at all.Anova(lm_earn)## Anova Table (Type II tests) ## ## Response: log_earn ## Sum Sq Df F value Pr(>F) ## ethnicity 9 3 3.74 0.011 ## height 76 1 99.24 <2e-16 ## Residuals 1243 1624We can verify this calculation in R
lm_earn_red <- lm(log_earn ~ height, data = earnings) a_full <- augment(lm_earn) a_red <- augment(lm_earn_red) sse_full <- sum(a_full$.resid^2) sse_red <- sum(a_red$.resid^2) df_full <- nrow(earnings) - 5 df_red <- nrow(earnings) - 2 f_star <- ((sse_red - sse_full) / (df_red - df_full)) / (sse_full / df_full) f_star## [1] 3.738pf(q = f_star, df1 = df_red - df_full, df2 = df_full, lower.tail = FALSE)## [1] 0.01079
\(F\)-test for lack of fit
If you have repeat observations at the same levels of predictor variables, then you can run a lack-of-fit test as before.
NOTE: You need to have repeat observations where all predictor levels are equal. E.g. this design matrix has no repeat observations: \[ \mathbf{X} = \begin{pmatrix} 1 & 55 & 13\\ 1 & 55 & 17\\ 1 & 43 & 13 \end{pmatrix} \] whereas this design matrix has repeat observations at one level (55 for the first predictor and 13 at the second). \[ \mathbf{X} = \begin{pmatrix} 1 & 55 & 13\\ 1 & 55 & 13\\ 1 & 43 & 13 \end{pmatrix} \]
Typically, you only have repeat observations like this in a controlled experiment.
It is nice to have such repeat observations specifically to test the adequacy of the linear model using an \(F\)-test lack-of-fit.
To demonstrate this test, consider the textile strength data from Shadid and Rahman (2010), which you can read about here and download from here.
textile <- read_csv("https://dcgerard.github.io/stat_415_615/data/textile.csv") glimpse(textile)## Rows: 56 ## Columns: 3 ## $ count <dbl> 24, 24, 24, 24, 24, 24, 24, 24, 24, 24, 24, 24, 24, 24, 24, 2… ## $ length <dbl> 2.70, 2.70, 2.70, 2.70, 2.74, 2.74, 2.74, 2.74, 2.80, 2.80, 2… ## $ strength <dbl> 7.90, 7.86, 7.85, 7.91, 7.38, 7.32, 7.37, 7.33, 7.30, 7.22, 7…The goal for these data is to study the effects of yarn-count and and stitch-length on fabric’s bursting strength.
library(GGally) ggpairs(textile)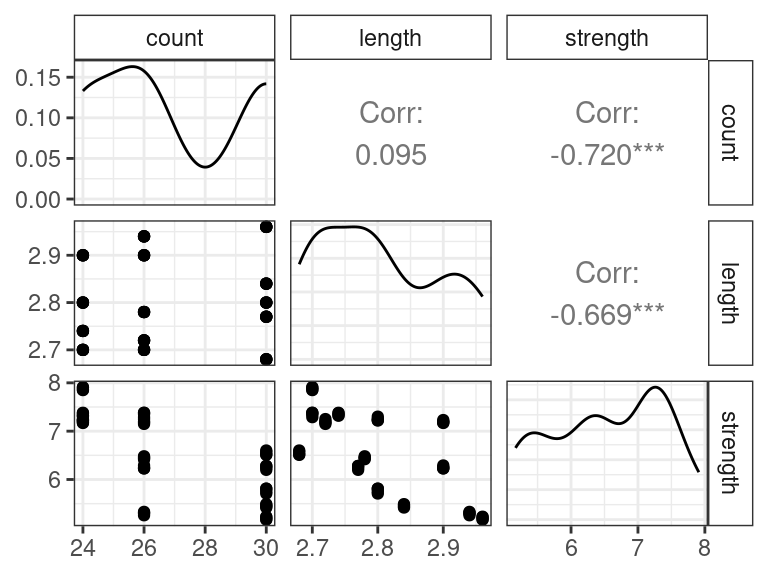
The notation for a lack-of-fit \(F\)-test is kind of clunky, so we’ll just discuss this test in intuitive terms.
The full model assumes that there is a separate mean bursting strength for each unique combination of yard-count and stitch length.
The reduced model assumes that the mean bursting strength is a linear function of yard-count and stitch length.
Here is a table demonstrating these two mean models
Yard-count Stitch Length Mean Full Mean Reduced 24 2.70 \(\mu_{1}\) \(\beta_0 + \beta_1 24 + \beta_2 2.7\) 24 2.74 \(\mu_{2}\) \(\beta_0 + \beta_1 24 + \beta_2 2.74\) 24 2.80 \(\mu_{3}\) \(\beta_0 + \beta_1 24 + \beta_2 2.8\) 24 2.90 \(\mu_{4}\) \(\beta_0 + \beta_1 24 + \beta_2 2.9\) 26 2.70 \(\mu_{5}\) \(\beta_0 + \beta_1 26 + \beta_2 2.7\) 26 2.72 \(\mu_{6}\) \(\beta_0 + \beta_1 26 + \beta_2 2.72\) 26 2.78 \(\mu_{7}\) \(\beta_0 + \beta_1 26 + \beta_2 2.78\) 26 2.90 \(\mu_{8}\) \(\beta_0 + \beta_1 26 + \beta_2 2.9\) 26 2.94 \(\mu_{9}\) \(\beta_0 + \beta_1 26 + \beta_2 2.94\) 30 2.68 \(\mu_{10}\) \(\beta_0 + \beta_1 30 + \beta_2 2.68\) 30 2.77 \(\mu_{11}\) \(\beta_0 + \beta_1 30 + \beta_2 2.77\) 30 2.80 \(\mu_{12}\) \(\beta_0 + \beta_1 30 + \beta_2 2.8\) 30 2.84 \(\mu_{13}\) \(\beta_0 + \beta_1 30 + \beta_2 2.84\) 30 2.96 \(\mu_{14}\) \(\beta_0 + \beta_1 30 + \beta_2 2.96\) Conceptually, we fit both models, obtain their error sum of squares for each, calculate the \(F\)-statistic, and compare this to the appropriate \(F\) distribution.
In the above example, the degrees of freedom of the full model is
n - 14since there are 14 parameters to estimate (14 \(\mu\)’s).The degrees of freedom of the reduced model is \(n - 3\), since there are only three \(\beta\)’s to estimate.
To compare these models in R, we first fit both models.
We fit the reduced model the usual way
lm_text <- lm(strength ~ count + length, data = textile)We fit the full model by first converting
countandlengthinto categorical variables.textile <- mutate(textile, count_cat = as.factor(count), length_cat = as.factor(length))We then use these categorical variables as covariates, but you do so by including interactions between covariates using
*(not+):lm_sat <- lm(strength ~ count_cat * length_cat, data = textile)- The
*means that there will be separate means for each unique combination of yard-count and stitch-length, instead of an additive effect for yard-count and a separate additive effect for stitch-length.
- The
Finally, we run
anova()(the base R version, not the{car}version), on these fitted models.anova(lm_text, lm_sat)## Analysis of Variance Table ## ## Model 1: strength ~ count + length ## Model 2: strength ~ count_cat * length_cat ## Res.Df RSS Df Sum of Sq F Pr(>F) ## 1 53 4.55 ## 2 42 0.05 11 4.5 335 <2e-16In the above, the SSE is called
RSSfor “residual sum of squares” (it’s confusing that software and books use different terminology, I know).The \(p\)-value is very small, indicating a lack-of-fit.
NOTE: This does not necessarily imply that the model is not useful. This just indicates that the variability within conditions is much smaller than the variability between conditions. Use residual plots to better determine lack-of-fit. In this example, we can still use a linear model to say things like “higher yard-count tends to have lower bursting strength” and “higher length tends to have lower bursting strength”. This might be all we need for our purposes.
Summary
If you have a full model and reduced model, which is a submodel of the full model (very important), then you can run an \(F\)-test with the null hypothesis being the reduced model.
The degrees of freedom for each model is the sample size minus the number of parameters in each model.
We calculate an \(F\)-statistic: \[ F^* = \frac{[SSE(R) - SSE(F)] / (df_r - df_f)}{SSE(F) / df_f} \]
Under \(H_0\) (the reduced model), the \(F^*\) follows an \(F(df_r - df_f, df_f)\) distribution.
Larger values of \(F^*\) provide evidence against the null, since then there is a bigger decline in the SSE between models than expected by chance alone.
The \(F\)-test encompases many situations as special cases
- Overall \(F\)-test. Use
glance()from the{broom}package. - \(F\)-test for one predictor. Use
Anova()from the{car}package and full model fit. - \(F\)-test for multiple predictors.
Fit both models, use
anova()to compare. - \(F\)-test for one categorical
variable. Use
Anova()from the{car}package on full model fit. - \(F\)-test lack-of-fit. Fit both
models, use
anova()to compare.
- Overall \(F\)-test. Use
Coefficient of Multiple Determination
The MLR model \[\begin{align} Y_i &= \beta_0 + \beta_1X_{i1} + \beta_2X_{i2} + \cdots + \beta_{p-1}X_{i,p-1} + \epsilon_i\\ E[\epsilon_i] &= 0\\ var(\epsilon_i) &= \sigma^2\\ cov(\epsilon_i, \epsilon_j) &= 0 \text{ for all } i \neq j \end{align}\]
Sums of Squares \[\begin{align} SSE &= SSE(X_1,X_2,\ldots,X_{p-1}) = \sum_{i=1}^n(Y_i - \hat{Y}_i)^2\\ SSR &= SSR(X_1,X_2,\ldots,X_{p-1}) = \sum_{i=1}^n(\hat{Y}_i - \bar{Y})^2\\ SSTO &= \sum_{i=1}^n(Y_i - \bar{Y})^2 \end{align}\]
Coefficient of multiple determination \[\begin{align} R^2 = \frac{SSR}{SSTO} = 1 - \frac{SSE}{SSTO} \end{align}\]
Proportionate reduction of total variation in \(Y\) associated with the use of the set variables \(X_1, X_2,\ldots,X_{p-1}\).
- I.e. a measure of the strength of association between \(Y\) and \(X_1,X_2,\ldots,X_{p-1}\).
\(0 \leq R^2 \leq 1\).
- Close to 0 when \(Y\) is only weakly associated with \(X_1,X_2,\ldots,X_{p-1}\).
- Close to 1 when \(Y\) is strongly associated with \(X_1,X_2,\ldots,X_{p-1}\).
Reduces down to the coefficient of simple determination when \(p = 2\) (SLR model).
Note, adding more \(X\) variables can only increase \(R^2\). So this cannot be used to compare two models with different number of predictors.
Adjusted coefficient of multiple determination: \[\begin{align} R^2_a = 1 - \left(\frac{n-1}{n-p}\right)\frac{SSE}{SSTO}. \end{align}\]
\(R_a^2\) might decrease as we add variables to the model if the reduction in SSE is offset by the decrease in degrees of freedom of the model.
- So, could potentially be used to compare different models.
Exercise: Does a high \(R^2\) indicate that multiple linear regression model is appropriate?
Coefficients of Partial Determination
Sums of squares have two uses
- Discussing proportionate decline in variability when you add a predictor.
- Hypothesis testing.
We already discussed hypothesis testing, let’s talk about proportionate decline.
The MLR model with two predictors \[\begin{align} Y_i &= \beta_0 + \beta_1X_{i1} + \beta_2X_{i2} + \epsilon_i\\ E[\epsilon_i] &= 0\\ var(\epsilon_i) &= \sigma^2\\ cov(\epsilon_i, \epsilon_j) &= 0 \text{ for all } i \neq j \end{align}\]
\(SSE(X_2)\) measures variation in \(Y\) when \(X_2\) is included in the model.
\(SSE(X_1, X_2)\) measures the variation in \(Y\) when both \(X_1\) and \(X_2\) are included in the model.
\(SSE(X_1, X_2) \leq SSE(X_2)\)
So the proportionate reduction in the variation in \(Y\) when \(X_1\) is added can be a measure of the contribution of \(X_1\).
Coefficient of partial determination \[\begin{align} R^2_{Y1|2} = \frac{SSE(X_2) - SSE(X_1,X_2)}{SSE(X_2)} = \frac{SSR(X_1|X_2)}{SSE(X_2)} \end{align}\]
Similarly, the proportionate reduction in the variation in \(Y\) when \(X_2\) is added, given that \(X_1\) is already in the model, is defined by \[\begin{align} R^2_{Y2|1} = \frac{SSE(X_1) - SSE(X_1,X_2)}{SSE(X_1)} = \frac{SSR(X_2|X_1)}{SSE(X_1)} \end{align}\]
General case \[\begin{align} R^2_{Y1|23} &= \frac{SSR(X_1|X_2, X_3)}{SSE(X_2, X_3)}\\ R^2_{Y2|13} &= \frac{SSR(X_2|X_1, X_3)}{SSE(X_1, X_3)}\\ R^2_{Y3|12} &= \frac{SSR(X_3|X_1, X_2)}{SSE(X_1, X_2)}\\ R^2_{Y4|123} &= \frac{SSR(X_4|X_1, X_2, X_3)}{SSE(X_1, X_2, X_3)}\\ &\text{etc...} \end{align}\]
Number to left of vertical bar (the \(|\) symbol) show the \(X\) variable being added.
The Numbers to the right of the vertical bar show the \(X\) variables already in the model.
First index is the response variable (\(Y\) in this case).
We can write out the coefficients of multiple determination using this notation as well. \[\begin{align} R^2_{Y1} &= \frac{SSR(X_1)}{SSTO}\\ R^2_{Y12} &= \frac{SSR(X_1, X_2)}{SSTO}\\ R^2_{Y123} &= \frac{SSR(X_1, X_2, X_3)}{SSTO}\\ &\text{etc...} \end{align}\]
Example: From the body fat example, we fit the model \[ Y_i = \beta_0 + \beta_1X_{i1} + \beta_2X_{i2} + \beta_3X_{i3} + \epsilon_i, \] where \(Y\) is fat, \(X_1\) is triceps, \(X_2\) is thigh, and \(X_3\) is midarm. We then obtain the Type I sums of squares using
anova().lmout <- lm(fat ~ triceps + thigh + midarm, data = body) anova(lmout)## Analysis of Variance Table ## ## Response: fat ## Df Sum Sq Mean Sq F value Pr(>F) ## triceps 1 352 352 57.28 1.1e-06 ## thigh 1 33 33 5.39 0.034 ## midarm 1 12 12 1.88 0.190 ## Residuals 16 98 6\(SSR(X_1) = 352\)
\(SSR(X_2|X_1) = 33\)
\(SSR(X_3|X_1, X_2) = 12\)
\(SSE(X_1, X_2, X_3) = 98\).
We have that
\(SSE(X_1) = SSE(X_1, X_2, X_3) + SSR(X_3|X_1, X_2) + SSR(X_2|X_1) = 98 + 12 + 33 = 143\)
\(SSE(X_1,X_2) = SSE(X_1, X_2, X_3) + SSR(X_3|X_1, X_2) = 98 + 12 = 110\)
\(SSR(X_1, X_2, X_3) = SSR(X_1) + SSR(X_2|X_1) + SSR(X_3|X_1, X_2) = 352 + 33 + 12 = 397\)
\(SSTO = SSR(X_1) + SSR(X_2|X_1) + SSR(X_3|X_1, X_2) + SSE(X_1, X_2, X_3) = 352 + 33 + 12 + 98 = 495\)
\[\begin{align} R^2 &= \frac{SSR(X_1, X_2, X_3)}{SSTO} = \frac{397}{495} = 0.80\\ R^2_{Y1} &= \frac{SSR(X_1)}{SSTO} = \frac{352}{495} = 0.71\\ R^2_{Y2|1} &= \frac{SSR(X_2|X_1)}{SSE(X_1)} = \frac{33}{143} = 0.23\\ R^2_{Y3|12} &= \frac{SSR(X_3|X_1,X_2)}{SSE(X_1, X_2)} = \frac{12}{110} = 0.11\\ \end{align}\]
So including a single variable (in this case, \(X_1\)) accounts for most of the variation decrease in Y at 71%. Including \(X_2\) in the model reduces the variation an additional 23%, and then including \(X_3\) in the model additionally reduces the variation by 11%
Changing the order that we fit the variables would change what coefficients of partial determination we could obtain.
Exercise: Consider the following ANOVA table with Type I Sums of Squares:
lmout <- lm(fat ~ thigh + triceps + midarm, data = body) anova(lmout)## Analysis of Variance Table ## ## Response: fat ## Df Sum Sq Mean Sq F value Pr(>F) ## thigh 1 382 382 62.11 6.7e-07 ## triceps 1 3 3 0.56 0.46 ## midarm 1 12 12 1.88 0.19 ## Residuals 16 98 6Remember that \(X_1\) is triceps, \(X_2\) is thigh, and \(X_3\) is midarm.
- What is SSR(X_2)?
- What is SSR(X_1|X_2)?
- What is SSR(X_3|X_1, X_2)?
- What is SSE(X_1, X_2, X_3)?
- What is SSE(X_2)?
- What is \(R^2_{Y2}\)?
- What is \(R^2_{Y1|2}\)?
Statistical versus Practical significance
Tests can have tiny \(p\)-values, but the effect sizes might be small.
- This can occur if we have a large sample size when two variables have a weak relationship.
Tests can have large \(p\)-values, but the effect sizes might be huge.
- This can occur if we have a small sample size when two variables have a strong relationship.
So never use \(p\)-values to describe the strength of the relationship between two variables.
- This is what other statistics like \(R^2\), partial \(R^2\), sums of squares, and Cohen’s \(d\) are meant for.
Only use \(p\)-values to describe the strength of the evidence that there is a relationship between two variables.
- This relationship might be very weak.
- The \(p\)-value tells you nothing about the strength of the relationship, just that one might exist.
Coefficients of determination are useful for determining practical significance.
Another tool to do this is to compare the effect sizes to the residual standard error.
- Recall: Residual standard error is the estimated population standard deviation.
- Recall: Residual standard error is the square root of the MSE.
Example: Recall the earnings data. Let’s read it in and fit a model for log-earnings on height:
library(tidyverse) earnings <- read_csv("https://dcgerard.github.io/stat_415_615/data/earnings.csv") earnings <- mutate(earnings, log_earn = log(earn)) earnings <- filter(earnings, is.finite(log_earn)) ggplot(data = earnings, mapping = aes(x = height, y = log_earn)) + geom_point()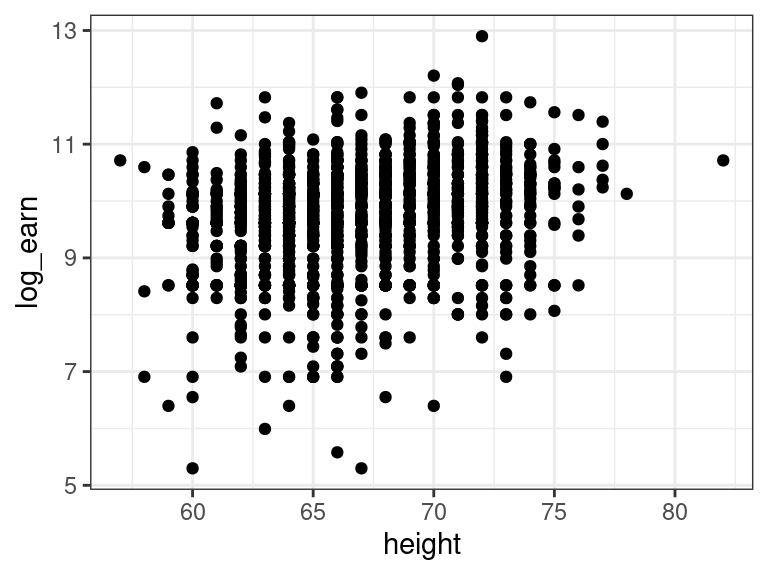
lm_earn <- lm(log_earn ~ height, data = earnings)library(broom) tidy(lm_earn)## # A tibble: 2 × 5 ## term estimate std.error statistic p.value ## <chr> <dbl> <dbl> <dbl> <dbl> ## 1 (Intercept) 5.91 0.376 15.7 6.70e-52 ## 2 height 0.0570 0.00562 10.1 1.65e-23The \(p\)-value is tiny. So is this a huge effect? Not really. Let’s discuss.
Individuals that are a whole foot taller earn about \(0.05704 \times 12 = 0.6845\) log-dollars more. This corresponds to about twice as much money ($e^0.6845 = 1.98). This seems large. However, let’s look at the residual standard deviation.
glance(lm_earn)$sigma## [1] 0.8772The residual SD is 0.8772. This is the average variability about the regression line and is larger even when comparing folks that are a full foot different in height.
If we compare prediction intervals between a 5’2’’ individual and a 6’2’’ individual (ignoring the appropriateness of the normal model for now), we have
predict(object = lm_earn, newdata = data.frame(height = c(5.2 * 12, 6.2 * 12)), interval = "prediction") %>% exp()## fit lwr upr ## 1 12938 2312 72387 ## 2 25652 4579 143718So it is true that the taller individual is expected to make twice as much money ($12,938 versus $25,652), but the range of individuals at each level is huge ($2312 to $72,387 and $4579 to $143,718). And this is on the larger side of comparisons between individuals (most individuals are less than a foot different).
A simpler measure would be to look a the \(R^2\).
glance(lm_earn)$r.squared## [1] 0.05954So only 5% of the variation in log-earnings can be explained by height. This is probably a good thing.
Conclusion: A small \(p\)-value does not mean there is a big effect.
Make plots, look at residual standard deviations, look at the \(R^2\) values, to determine if an effect is practically significant.
Exercise
From the estate data, let’s consider the association
between log-price, the number of beds, and the number of baths.
estate <- read_csv("https://dcgerard.github.io/stat_415_615/data/estate.csv")
estate <- mutate(estate, log_price = log(price))
estate <- select(estate, log_price, bed, bath)
glimpse(estate)## Rows: 522
## Columns: 3
## $ log_price <dbl> 12.79, 12.74, 12.43, 12.23, 12.53, 12.42, 12.35, 11.92, 12.1…
## $ bed <dbl> 4, 4, 4, 4, 4, 4, 3, 2, 3, 3, 7, 3, 5, 5, 3, 5, 2, 3, 4, 3, …
## $ bath <dbl> 4, 2, 3, 2, 3, 3, 2, 1, 2, 3, 5, 4, 4, 4, 3, 5, 2, 4, 3, 3, …We will consider regressing log-price (\(Y\)) on number of beds (\(X_1\)) and number of baths (\(X_2\)).
Make a pairs plot and explore the association between these variables. What do you conclude?
Create an ANOVA table that contains \(SSR(X_2)\), \(SSR(X_1|X_2)\), and \(SSE(X_1, X_2)\). State what each of these are numerically.
Calculate the SSTO from this output.
What proportion of variation in \(Y\) can be explained by \(X_2\)?
What is the proportionate decrease in variation when we add \(X_1\) to the model that already contains \(X_2\)?
How strong is the association between log-price and the predictors?
For each row of the above ANOVA table, state the full and reduced models of the hypothesis tests.
For each row of the above ANOVA table, state the conclusions of the hypothesis tests.
Conduct an overall \(F\)-test for the model. \[ Y_i = \beta_0 + \beta_1X_{i1} + \beta_2 X_{i2} + \epsilon_i. \] State the hypotheses and conclusions.
Is it possible to run an \(F\)-test lack-of-fit for the model \[ Y_i = \beta_0 + \beta_1X_{i1} + \beta_2 X_{i2} + \epsilon_i? \] If so, conduct one, stating the hypotheses and conclusions.